Table of Contents
TLDR: LLMOps is the operational discipline for running production-grade AI systems built on large language models. Without it, output quality degrades, token costs spiral, and compliance gaps accumulate silently. Teams shipping without structured LLM operations face compounding technical debt within 90 days of launch.
Shipping an LLM demo takes a weekend. Keeping it reliable in production takes a system.
That gap is exactly why LLMOps exists. Many enterprises have adopted AI across business functions, yet production failure rates remain high because the operational infrastructure to run, monitor, and control models was never built.
Deploying large language models without structured operations is like running a hospital without triage. You get patients through the door. You just can't guarantee what happens next.
This blog explains what LLMOps actually covers, what it costs, where teams get burned, and how to pick a partner who delivers it in production, not just on a slide deck.
LLMOps is the set of practices, tools, and workflows that manage large language model systems from development to production, covering prompt versioning, output monitoring, cost control, and compliance beyond traditional MLOps.
LLMOps refers to operationalizing LLM-based applications so they stay accurate, cost-efficient, and auditable at scale. Think of it as the production layer that sits between your LLM API and your end users. It handles what happens after the model call: did the output meet quality thresholds? Did the token spend match projections? Was sensitive data logged correctly?
What LLMOps Replaces or Extends
Traditional LLM operations evolved from MLOps, but MLOps was designed for batch inference on tabular data. It had no concept of a prompt, no mechanism for model evaluation on open-ended text, and no cost-per-token accounting. Deploying large language models fills those gaps directly.
How LLMOps Differs from MLOps and DevOps
| Dimension | DevOps | MLOps | LLMOps |
| Primary artifact | Code | Model weights | Prompts + model weights |
| Monitoring focus | Uptime, latency | Accuracy, data drift | Output quality, token cost, and hallucination detection |
| Version control | Git | Dataset + model versions | Prompt versions + model versions |
| Compliance layer | Auth/access | Data lineage | Input/output audit logs |
Key Terminology Glossary
Prompt versioning tracks every change to prompts, like Git for model instructions. Model evaluation validates output quality before release. LLM observability provides runtime visibility into outputs. Model drift monitoring flags unexpected changes. These form the core of a mature setup.
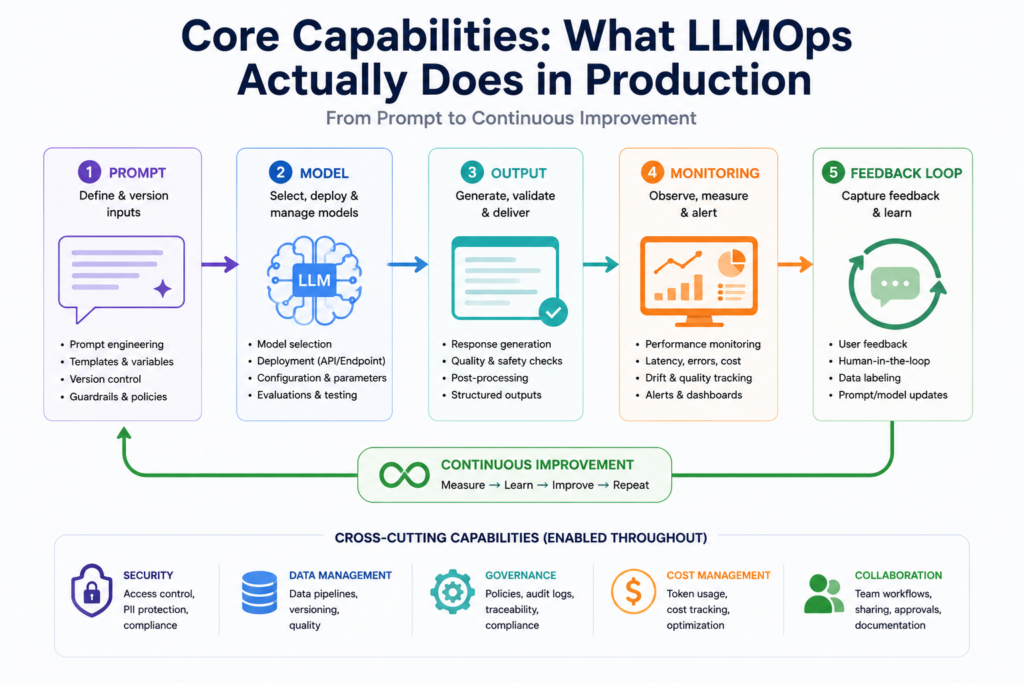
Every prompt change is a deployment. Teams treating prompts as Notion sticky notes will break production. Proper prompt versioning means every prompt carries a version ID, a test result, a rollback path, and an owner. Tools like PromptLayer and Langfuse handle this natively inside LLMOps pipelines.
Model evaluation in LLMOps is not a test-set accuracy check. You need rubric-based scoring, human-in-the-loop review for edge cases, and automated regression testing before every version ships. The quality gate exists for one reason: blocking bad output before users see it.
LLM observability surfaces what your model actually returns under real traffic. Response latency, refusal rates, topic drift, and cost-per-session are signals standard APM tools miss entirely. LLM monitoring tools like Arize Phoenix catch degradation in real time. Without them, users find the problems before you do.
A fine-tuning pipeline without orchestration is a one-time experiment, not a production capability. Repeatable fine-tuning covers data curation, training run tracking, baseline evaluation, and safe rollout as a defined process for deploying large language models.
LLM deployment best practices include canary releases, fallback routing, PII scrubbing before inference, and token budget enforcement per session. At enterprise scale, these separate a real product from a demo.
The four failure modes that make LLMOps non-negotiable in 2026 are silent degradation, prompt-driven outages, uncontrolled token spend, and compliance exposure from unlogged inference. Each stays invisible until it causes real damage.
Model providers update base models without notice. Output formats shift. Without LLM monitoring tools, your application drifts from acceptable to broken while dashboards show green. That is model drift monitoring in practice: you are not watching the model, you are watching the cost of ignoring it.
One prompt edit changes output tone, format, or factual grounding across every user session. Without prompt versioning, there is no rollback, diff, or audit trail. Teams debug by guessing. That is an expensive weekend.
A misconfigured context window or runaway summarization loop multiplies LLM operations spent by 10x overnight. Proper LLMOps cost attribution stops this before it reaches your cloud bill.
GDPR, HIPAA, and SOC 2 require audit trails. Deploying large language models in regulated industries without input/output logging is non-compliant by default. No LLM operations logging means no defensible position during an audit.
Selection of the wrong operational model for LLM operations costs more than the tooling itself. It costs engineering time, incident recovery, and delayed launches.
MLOps platforms like MLflow handle model registry, experiment tracking, and deployment pipelines for structured models. They have no native support for prompt management, LLM observability, or token cost tracking through LLM monitoring tools. Using MLflow alone is like using a scalpel to do carpentry. The tool is real, but the fit is wrong for deploying large language models.
Manual deployment works at demo scale. At the production scale, it means no rollback, no eval gates, no cost control, and no audit log. Every incident becomes a fire drill. Teams that outgrow manual scripts typically lose 3 to 6 months of engineering velocity, rebuilding what a proper platform would have provided on day one.
OpenAI, Anthropic, and Google provide model access. They do not provide prompt versioning, output quality monitoring, cost attribution by team or feature, or compliance logging. LLM operations infrastructure fills exactly that gap. The API is the engine.
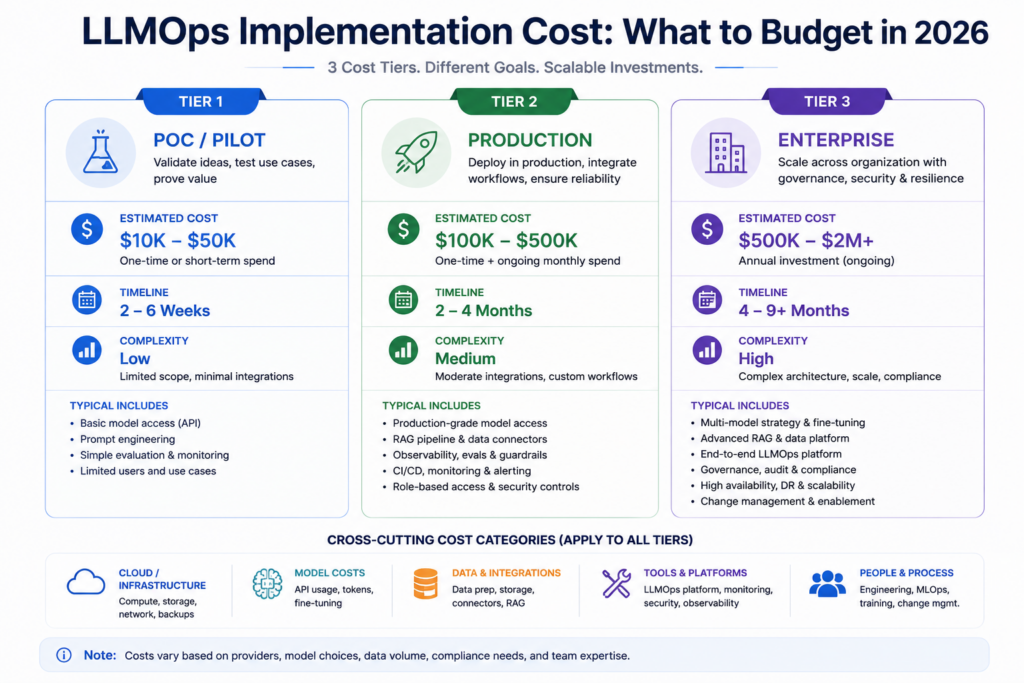
The implementation costs range from $8,000 for a startup POC to $500,000+ for an enterprise multi-model platform. The variance is real and driven by observability depth, fine-tuning compute, and contract structure.
Price: 8,000 to 25,000
This tier covers a single-model deployment with basic prompt versioning, one eval pipeline, and lightweight LLM monitoring tools. Timeline is 4 to 8 weeks. It is enough to prove a concept and catch the most obvious failure modes. It is not enough for regulated industries or multi-team usage to deploy large language models.
Price: 30,000 to 90,000
This is where most mid-market implementations land. You get full LLM observability, automated model evaluation with quality gates, a fine-tuning pipeline, cost attribution dashboards, and documented LLM deployment best practices. The timeline is 3 to 5 months.
Price: 100,000 to 500,000+
Enterprise LLMOps platforms handle multiple base models, multiple internal teams, compliance logging for GDPR/HIPAA, private model hosting, and full audit trails. Timeline is 6 to 18 months. The cost is justified by risk avoidance alone in regulated sectors.
| Cost Category | Typical Range |
| Observability tooling licenses | $500 to $5,000/month |
| Fine-tuning compute (GPU hours) | $2,000 to $20,000/run |
| Compliance logging storage | $200 to $2,000/month |
| Engineering ramp-up time | 40 to 120 hours |
Fixed-price contracts work for Tier 1 and Tier 2 with a well-defined scope. Managed retainer models suit enterprise LLMOps where the scope evolves with the platform, especially when deploying large language models at scale. Get the scope locked before signing either.
LLMOps delivers measurable ROI through four levers: lower cost per query, faster feature launches, fewer production incidents, and better scalability economics. None of these are soft benefits, and LLM operations make this impact measurable in production.
Smart model routing in an LLMOps platform directs simple queries to cheaper, smaller models and complex ones to flagship models. This alone cuts LLM inference costs by 30 to 60% in typical production setups without touching output quality.
Teams with mature LLM operations ship new LLM features 40 to 60% faster than those managing deployments manually. Prompt versioning, automated eval pipelines, and rollback capability remove the friction that slows every release.
LLM monitoring tools catch output degradation before users report it. Mean time to resolution drops when model drift monitoring surfaces anomalies in real time versus after the fact. One missed incident in a customer-facing LLM product can cost more than a year of tooling.
LLMOps infrastructure scales with usage, not headcount. A well-architected platform handles 10x traffic growth without a proportional increase in operational overhead. That is the scalability argument that lands with CFOs, supported by LLM monitoring tools' insights.

The implementation carries real risks. Teams that underestimate these end up with expensive toolchains that do not hold together under production load.
The LLMOps tooling market is fragmented. Orchestration, observability, serving, and eval tools come from different vendors with different data models. Integration overhead is real. Budget 20 to 30% of implementation time for glue work.
Hallucination detection is unsolved at scale. Current approaches use rubric scoring, reference-based evaluation, and human review sampling. None of these is perfect for deploying large language models. Any vendor claiming zero-hallucination detection at production scale is overselling.
Model drift for LLM monitoring tools is harder than for classification models because there is no clean ground truth label. Proxy metrics like output length distribution, refusal rates, and user correction signals are used instead. They are useful but imperfect.
Deploying large language models across geographies introduces data residency requirements that most LLMOps stacks are not configured for by default. GDPR Article 44 transfer restrictions apply to inference logs as much as to training data. Build this requirement into the architecture from day one.
Picking an LLMOps partner is a 12 to 24-month commitment. The wrong choice costs more in remediation than the original contract.
Use this checklist before signing:
The LLMOps market is maturing fast, with clear differentiation emerging across implementation partners, tooling specialists, and full-platform providers. Here are the vendors worth evaluating.
Patoliya Infotech delivers complete LLMOps implementation for mid-market and enterprise teams, covering the full stack from prompt versioning and model evaluation to LLM deployment best practices and compliance logging.
Full-lifecycle LLMOps partner with production deployment experience across healthcare, fintech, and SaaS verticals.
Key Features:
Best For: Mid-market to enterprise teams deploying large language models who need a single partner for strategy, build, and ongoing operations.
Client Review: 4.9/5
Modular ML and BentoML-focused partners specialize in model serving infrastructure for it at scale.
High-performance LLMOps serving layer built on BentoML and vLLM for teams with demanding latency and throughput requirements.
Key Features:
Best For: Engineering teams that have a model but need production-grade serving infrastructure under their LLMOps stack.
Client Review: 4.7/5
Arize AI and its open-source counterpart Phoenix are purpose-built LLM monitoring tools for LLM observability and evaluation.
Leading LLMOps observability platform with native support for tracing, eval, and hallucination detection workflows.
Key Features:
Best For: Data science and ML engineering teams that need deep observability without building LLM monitoring tools from scratch.
Client Review: 4.8/5
W&B-specialized implementation partners bring experiment tracking and model evaluation infrastructure to pipelines.
LLMOps implementation leveraging Weights & Biases for experiment tracking, prompt versioning, and fine-tuning pipeline management.
Key Features:
Best For: Research-heavy teams or organizations already using W&B that want structured LLM operations without switching toolchains.
Client Review: 4.6/5
We deliver full-lifecycle LLMOps implementation, from prompt versioning and model evaluation through LLM observability and compliance logging, with production references across regulated and high-scale environments.
If your team is evaluating LLMOps implementation this quarter, schedule a technical scoping call with Patoliya Infotech. Bring your stack, your compliance requirements, and your timeline. The conversation will define the scope before any commitment.
LLMOps is not optional for any team deploying large language models beyond a pilot. The gap between a working demo and a reliable product is exactly what structured LLM operations fill.
Token costs spiral without attribution. Output quality drifts without LLM monitoring tools. Compliance gaps accumulate without inference logging. Engineering velocity stalls without prompt versioning and automated eval. Every week without this infrastructure adds debt that compounds.
The teams building it now are not ahead of the curve. They are just avoiding the crash.
Let's scope your LLMOps implementation. Book a technical call with Patoliya Infotech.