Table of Contents
TLDR: Synthetic data generation creates statistically realistic datasets with zero real personal records, solving data scarcity, labelling cost, and compliance in one move. Adoption is accelerating as teams prioritize automation, visibility, and cost-efficient scaling. This guide covers how it works, which tools lead in 2026, and what implementation actually costs.
Synthetic data AI is becoming essential for modern model development. Real datasets are costly to label, restricted by GDPR and HIPAA, and often too imbalanced for production use. Teams relying only on real data face delays in training and deployment. Teams waiting for clean real data miss deployment windows that their competitors do not.
Synthetic data AI removes that bottleneck at the source. This guide covers what synthetic data generation is, how it works, which tools dominate in 2026, and what it costs to implement at scale to generate test data. By the end, you will have a vendor comparison framework, a cost benchmark, and a checklist to evaluate synthetic data generation solutions for your pipeline.
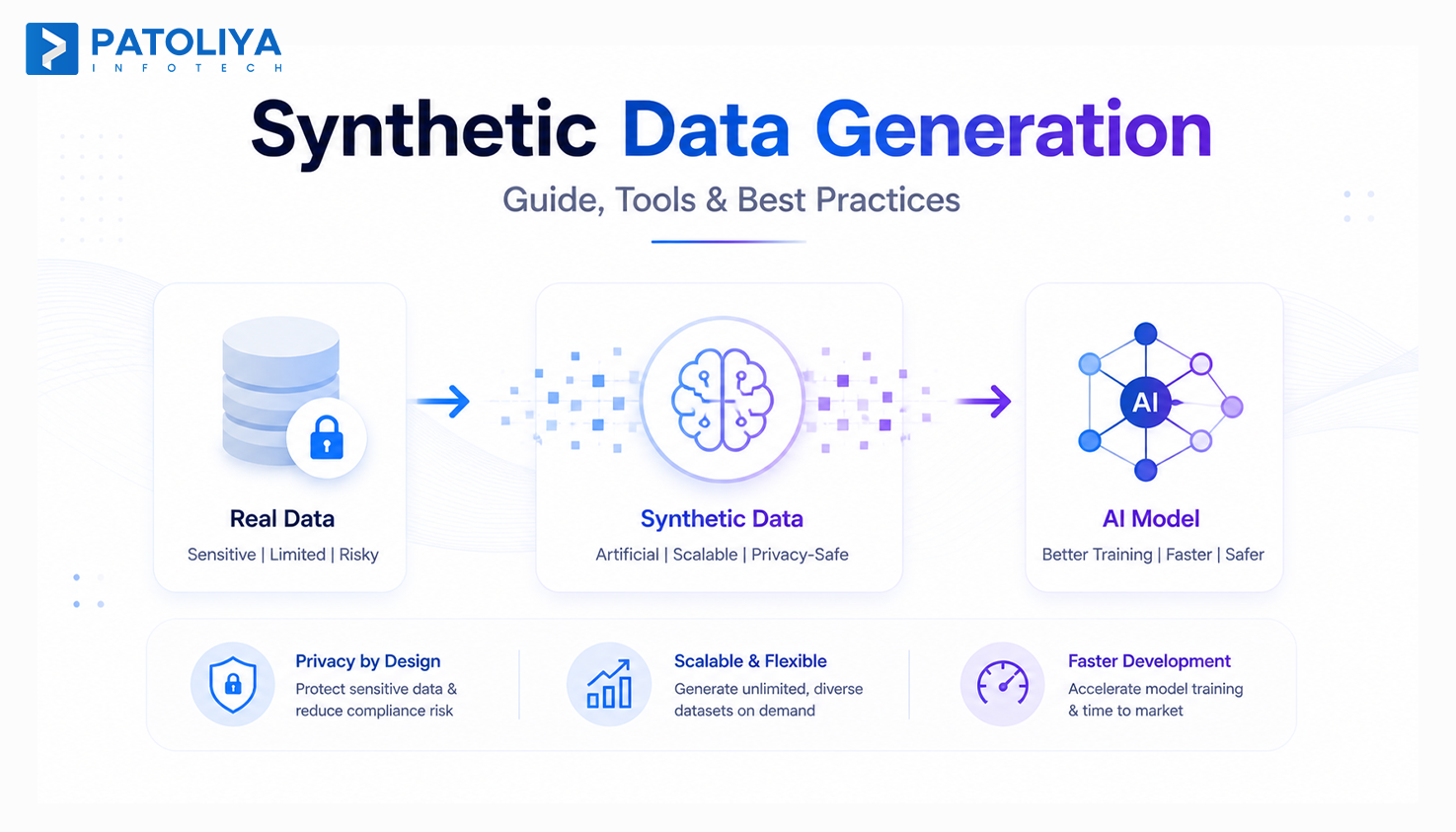
Synthetic data generation is the process of creating artificial datasets that mirror the statistical properties and relationships of real data without containing any actual personal records.
The mechanism depends on the data type. For tabular data, GANs and VAEs learn underlying distributions and produce new rows. For images, diffusion models generate pixel-level, realistic outputs. For text, fine-tuned LLMs produce privacy-compliant data at scale.
What separates synthetic data generation from random data generation is fidelity. A good synthetic data AI system preserves the correlation between age and income, or between transaction frequency and fraud probability, while generating records that never existed.
The question for engineering teams is not whether synthetic data generation works. Waymo runs the majority of its object detection training on synthetic images. The question is which modality and compliance architecture fits your pipeline.

Tabular synthetic data generation is the most mature modality available today. Platforms like MOSTLY AI and Gretel.ai produce realistic synthetic records from structured CSVs and SQL exports while preserving referential integrity across tables.
Teams generate test data synthetically in hours instead of waiting days on masking workflows that break foreign key relationships anyway.
Computer vision pipelines need a labeled image volume that manual annotation cannot supply fast enough.
Synthetic data AI using diffusion models generates pre-labeled training images at scale, helping teams use fake data for machine learning across rare-class edge cases.
Data augmentation through synthetic data generation fills class gaps for low-light detection, manufacturing defect inspection, and autonomous vehicle perception models.
NLP teams rely on fake data for machine learning to produce domain-specific corpora and adversarial examples without exposing proprietary data.
Fake data for machine learning in text form covers low-resource language gaps and fine-tuning needs that real data collection cannot fill at a reasonable cost or within compliance boundaries in regulated industries.
Financial transaction streams and IoT logs are difficult to share due to compliance constraints. Synthetic data generation for time-series enables teams to generate test data while preserving temporal patterns, seasonality, and anomaly distributions.
This makes it viable as model training data for fraud detection and predictive maintenance, where real data access requires weeks of legal approval before a single training run starts.

Data anonymization removes identifiers but still carries re-identification risk. Fake data for machine learning avoids this entirely by never using real records.
Data augmentation improves existing data. Synthetic data generation expands beyond its limits entirely.
Real data collection remains the fidelity standard. Synthetic data generation solves the timing and access constraints that block it.
| Platform | Free Tier | Mid Tier | Enterprise |
| MOSTLY AI | Yes | ~$500/month | Custom |
| Gretel.ai | Yes | $500–$2,000/month | Custom |
| YData | Yes (open source) | $300–$1,500/month | Custom |
| Hazy | No | From $2,000/month | Custom |
| Synthesis AI | No | Custom only | Custom |
Custom synthetic data generation implementations run $30,000 to $100,000 for initial scoping and generative model training. Ongoing maintenance costs $2,000 to $5,000 per month. Source: Clutch and GoodFirms AI benchmarks, Q1 2025. These apply to full-stack builds. SaaS-only deployments for teams just starting to generate test data synthetically sit at the lower end.
Three cost lines teams consistently miss:
Most synthetic data AI vendors offer monthly billing with 15 to 25% annual discounts. Enterprise contracts carry minimum row or API call commitments. Verify whether pricing covers generate test data use cases, and production model training separately. Some vendors tier these differently, and the gap between quoted and actual cost at scale is high.
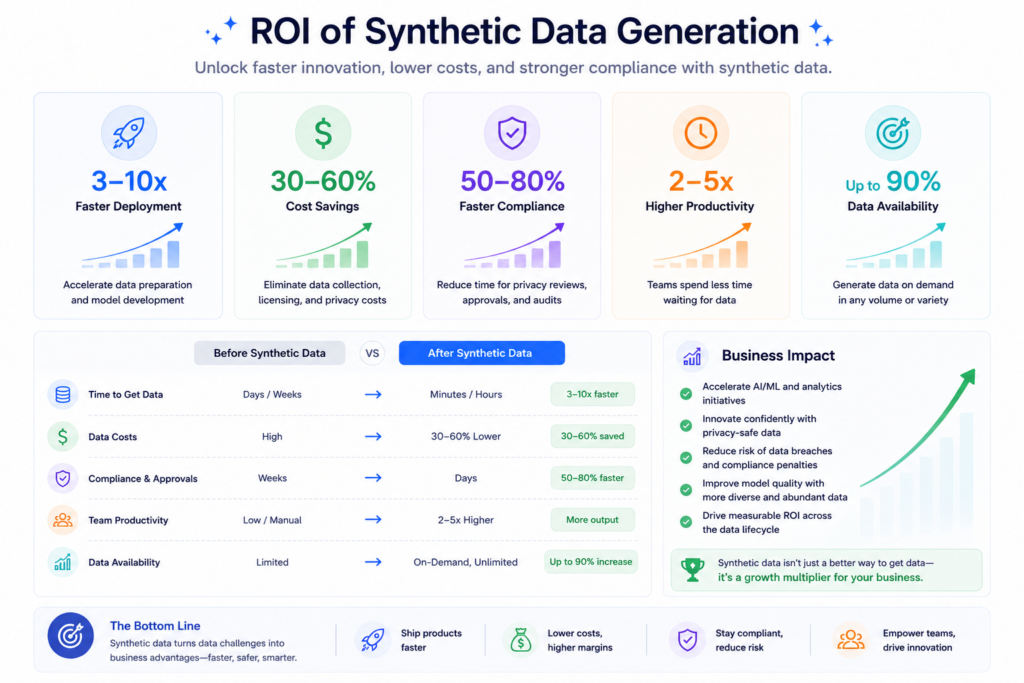
Pre-labeled output from synthetic data generation eliminates annotation spend for generated data. A team producing 200,000 synthetic images avoids $10,000 to $30,000 in labeling costs per training cycle. That saving repeats every cycle with no additional effort to generate test data.
Data access approvals in regulated industries take 4 to 12 weeks on average. Synthetic data AI removes that dependency completely. Teams begin model development the same week instead of waiting for legal clearance. Fake data for machine learning that required months of procurement can be generated in days.
Synthetic data generation eliminates GDPR processing obligations in development entirely. No real personal data means no breach notification risk and no DPA review before training begins with generate test data. Teams in healthcare and finance using fake data for machine learning report a 60 to 80% reduction in legal review cycles before model approval.
Real data collection costs scale linearly with volume. Synthetic data generation scales at marginal cost after the initial generative model is trained. Ten million synthetic rows costs roughly the same compute as one million. For growing model training data requirements, that economic gap compounds with every additional training run.
Higher statistical fidelity in synthetic data generation means the output more closely resembles real records, which increases the re-identification risk of fake data for machine learning.
Tools maximizing fidelity for model accuracy can reduce data anonymization strength. Measure both metrics during evaluation. Most platforms let you tune the trade-off explicitly.
Synthetic data AI trained on biased real data amplifies those biases in output. A hiring dataset with gender bias produces synthetic records with stronger gender bias.
Bias auditing using Fairlearn or IBM AI Fairness 360 before production deployment is non-negotiable regardless of which synthetic datasets tools you use.
Synthetic data generation is not universally accepted across all regulatory contexts. FDA clinical submissions and some financial filings still require real-data validation alongside fake data for machine learning.
Verify regulatory acceptance for your specific jurisdiction before committing to a synthetic-first pipeline in a compliance-sensitive context of generate test data.
Several synthetic data generation platforms use proprietary architectures that complicate migration. Verify that generated data and trained generative models are exportable before signing enterprise contracts.
The ability to generate test data portably matters as much as generation quality when evaluating long-term vendor fit for fake data for machine learning.
Run this before any synthetic data generation purchase decision:
A 2-week paid proof of concept on your real sample data is the only reliable quality test for data generation.
An enterprise synthetic data generation platform for tabular data, widely used across European financial services and insurance.
Key Features:
Best For: Financial services and insurance teams needing GDPR safe testing data for QA and model training through generate test data.
Pricing: Free tier available. Enterprise from $500/month.
Rating: 4.7/5
Developer-first synthetic data generation platform with API and SDK support for tabular and text generation across cloud environments.
Key Features:
Best For: ML engineering teams wanting programmable generate test data with strong privacy guarantees baked in.
Pricing: Free tier. Mid-tier from $500/month. Enterprise custom.
Rating: 4.6/5
Specializes in synthetic image and video synthetic data generation for computer vision pipelines, including human-centric perception model training.
Key Features:
Best For: Computer vision teams needing labeled synthetic datasets tools at scale for detection and perception models.
Pricing: Custom enterprise only.
Rating: 4.4/5
Enterprise tabular synthetic data generation built for UK and EU financial institutions with strong FCA and EBA regulatory positioning.
Key Features:
Best For: UK and EU banks where compliance documentation matters as much as data quality for generating test data workflows.
Pricing: Enterprise custom only.
Rating: 4.3/5
Open-source and enterprise synthetic data generation focused on data augmentation for structured and time-series data pipelines.
Key Features:
Best For: Teams wanting open-source flexibility with optional enterprise support and no upfront vendor commitment to generate test data.
Pricing: Open source is free. Enterprise from $300/month.
Rating: 4.5/5
Building a pipeline that produces fidelity-validated, bias-audited, privacy-compliant data at production scale takes weeks without the right implementation experience.
We implement synthetic data generation infrastructure for ML teams in financial services, healthcare, and enterprise SaaS. Every engagement delivers:
Most teams reach a validated proof of concept within 3 to 6 weeks on a scoped delivery timeline.
If your team is evaluating synthetic data generation vendors, let's map your pipeline requirements in one technical call.
Synthetic data generation has moved from experimental workaround to production infrastructure. The market hit $380M in 2024 and is projected to reach $1.1B by 2028. The decision is no longer whether to adopt synthetic data AI, but which modality and vendor model fits your pipeline. Teams still waiting on real data access approvals are losing development cycles that do not return. Schedule a technical scoping call with Patoliya Infotech and receive a benchmarked implementation plan within 5 business days.