Table of Contents
TL;DR: A RAG pipeline pulls real documents into the model's context before it answers, so the reply comes from your own data instead of a guess. Skip this step, and you get fluent answers that are confidently wrong. Build it right, and your product stops guessing on the questions customers ask most.
Organizations often focus on the model when an AI assistant produces inaccurate answers, while the actual problem frequently originates in the RAG pipeline supplying the model with context. A weak retrieval step buries the right answer under five irrelevant documents, and no model writes its way out of that.
This guide breaks down what a RAG pipeline does, where retrieval augmented generation beats fine-tuning, what it costs to build in 2026, and how to pick a partner who will not waste your budget on a demo that never reaches production.
A RAG pipeline retrieves relevant documents from your data and hands them to the model before it answers. That is the whole idea. Everything else is implementation detail.
Before retrieval augmented generation became standard, teams stuffed manuals into the prompt or fine-tuned a model on static knowledge. Both broke the moment content changed. A RAG pipeline updates the index, not the model, so fresh content shows up in answers within minutes.
RAG vs Fine Tuning vs Long Context Prompting
Long context prompting works for ten documents and fails at ten thousand, since cost and accuracy both drop as input grows. A RAG pipeline scales because it searches first and reads only what matters.
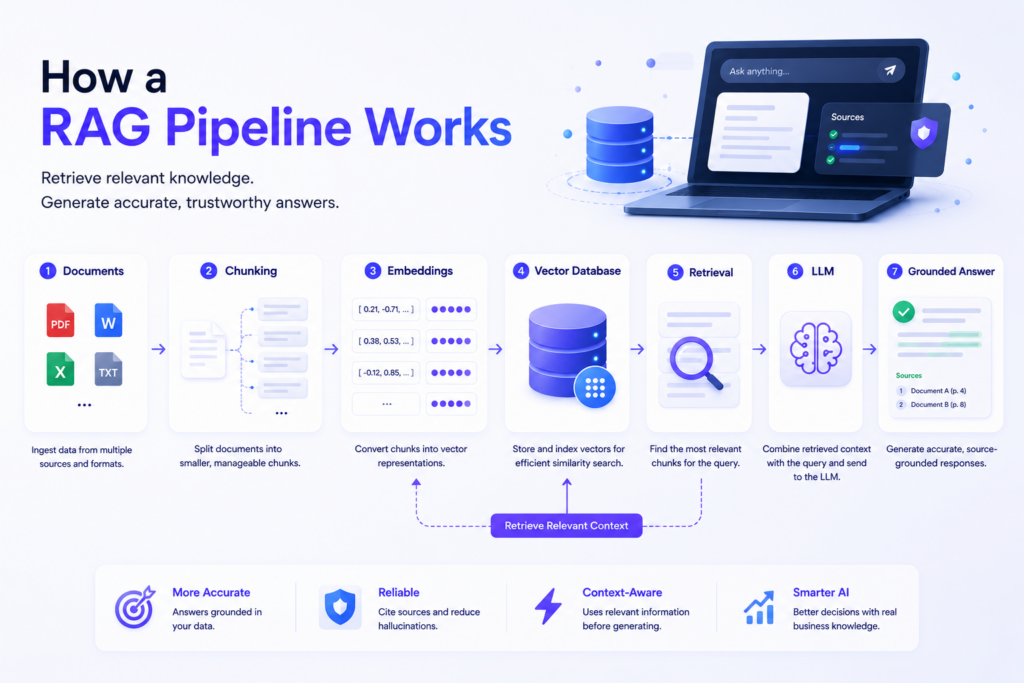
A general model guesses on your pricing or warranty terms since it never saw that data. A RAG pipeline hands it your real policy document at answer time, so it writes from your text, not a guess. That is retrieval augmented generation in action.
Pricing and policies change weekly at most companies, but a model trained months ago has no idea your return window changed. A RAG pipeline reads from a live index, so answers reflect today's policy, not last quarter's.
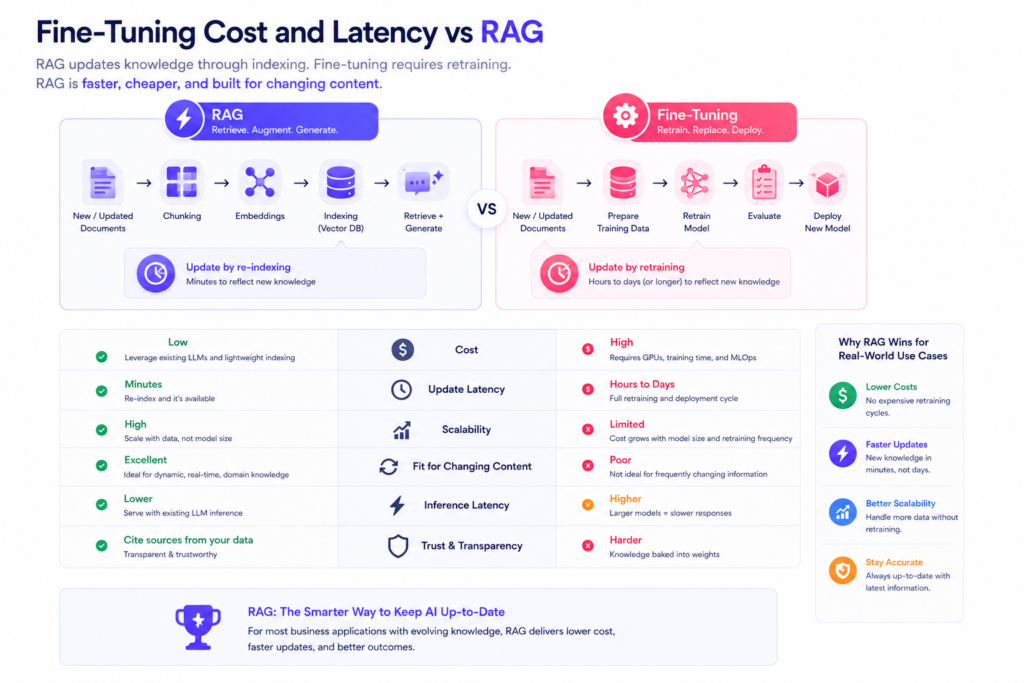
Retraining a model every time content changes gets expensive and slow. A RAG pipeline separates knowledge from behavior, so you update an index in minutes instead of retraining for days.
A fine-tuned model cannot show which document produced an answer. A RAG pipeline returns the source passage alongside the answer, giving regulators an audit trail they will accept.
Long context windows made some predict the end of retrieval, but usage tells a different story. Context windows get expensive and less accurate as documents pile up, so a well-built retrieval augmented generation keeps token cost predictable while accuracy holds steady.
Teams now pair keyword search with vector search inside the same RAG pipeline, since pure semantic search misses exact matches like part numbers. Most wire this together with a LangChain RAG framework instead of building retrieval logic from scratch.
The real RAG vs fine-tuning decision comes down to adding knowledge versus changing behavior. A support bot that needs your brand voice benefits from light fine-tuning layered on top of a RAG pipeline, not instead of one.
| Architecture | Best For | Knowledge Freshness | Key Risk |
| RAG pipeline | Frequent knowledge changes, source citation required | Fresh, index update only | Retrieval quality and chunking errors |
| Fine Tuning | Changing model tone or output format | Stale until retrained | Cost, model drift, no citations |
| Long Context Prompting | Small, static document sets | Fresh if resupplied each call | Token cost balloons on long input |
| Agentic Memory | Multi-session personalization | Continuously updated | Immature tooling, governance gaps |
Pilot or Proof of Concept Tier: A scoped pilot covering one data source and one use case typically runs six to eight weeks. This tier proves the build RAG with LLM concept works on your content before a bigger build. Most teams use this stage to test retrieval accuracy, not polish.
Mid Complexity Production Tier: This tier adds hybrid retrieval, monitoring, and at least one production integration, usually spanning three to six months. Teams that build RAG with LLM integrations here need real evaluation tooling, not guesswork, since errors reach real customers fast.
Enterprise Grade Tier: Enterprise-grade builds add multiple indexes, strict access control, and integration across several systems, often taking six to twelve months. An enterprise RAG pipeline at this scale needs dedicated infrastructure and a team that has shipped one before.
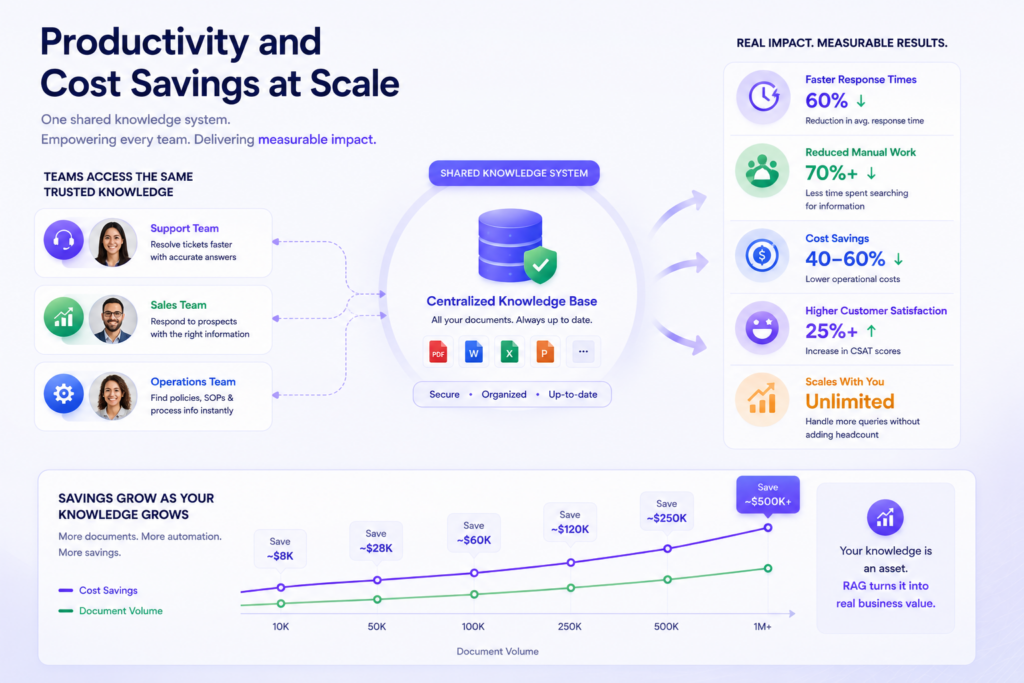
Hidden Costs Buyers Miss: Most quotes cover build time but skip ongoing reindexing, evaluation tooling, and the time spent fixing chunking after launch. A RAG pipeline is never finished; it needs tuning as content and user questions evolve.
Contract Models: Fixed bid works for a tightly scoped pilot, while time and materials fits better once a RAG pipeline moves into ongoing production tuning. Teams that build RAG with LLM vendors on retainer avoid surprise invoices later.
IP and data exposure risk is real, sending proprietary documents through a third-party embedding or model API without a signed data use agreement is the fastest way to lose control of your content. Name who can train on your data in writing before any RAG pipeline work starts.
Retrieval tuning with offshore or distributed teams needs constant back and forth between whoever owns the content and whoever owns the code, and time zone gaps slow that loop.
A team trying to build RAG with LLM integrations across scattered time zones without a shared review cadence ships a RAG pipeline late, with quality issues nobody caught early.
Most failed build RAG with LLM projects fail quietly, returning plausible but wrong answers instead of obvious errors anyone would catch. Bad chunking and untested retrieval augmented generation settings are the usual cause.
Some vendors retain rights to the retrieval code they build for you, which traps you with that vendor for every future update. Demand full source code ownership for any RAG pipeline you pay to build, written into the contract before work begins.
Use this list before signing anyone to build your retrieval augmented generation, since most failed projects trace back to a skipped item here.
Production RAG Deployments: Ask for two live examples, not slide deck case studies.
Hybrid Retrieval Capability: Confirm keyword and vector search both ship by default.
Documented Evaluation Framework: They should show how they measure answer accuracy for the RAG pipeline they propose.
Security and Compliance Certifications: Get the actual certificate names, not a general claim.
Vector Database Flexibility: Avoid lock-in to one storage vendor you cannot switch later.
Transparent Pricing Model: A clear split between build cost and ongoing maintenance cost.
Source Code and IP Ownership: Full ownership transfers to you, in writing.
Post Deployment Support: A defined tuning plan after launch, not silence once invoices stop.
Industry-Specific Reference Architecture: Real experience in your regulatory environment.
Realistic Timeline Commitments: Be wary of anyone promising a production RAG pipeline in two weeks.
Full lifecycle AI shop that runs pilots through production fine-tuning under one roof, with a research bench backing every RAG pipeline build.
Key Features:
Industries Catered: Technology, SaaS, enterprise AI.
Pricing: $20K to $80K for pilot, scoped quote for production.
Clutch Review: 4.9/5 stars based on 20 verified reviews.
AWS-certified engineering team that builds compliance-aligned RAG pipeline architecture for companies already running on AWS infrastructure.
Key Features:
Industries Catered: Healthcare, finance, regulated enterprise SaaS.
Pricing: Scoped quote based on integration count.
Clutch Review: 4.8/5 stars based on 9 verified reviews.
Offshore hybrid team split between San Francisco and India, built for multimodal retrieval that goes beyond plain text documents.
Key Features:
Industries Catered: Media, retail, global enterprise.
Pricing: Scoped quote based on project complexity.
Clutch Review: 4.7/5 stars based on 9 verified reviews.
HIPAA compliant retrieval specialist for healthcare and fintech clients where regulatory documentation carries as much weight as speed.
Key Features:
Industries Catered: Healthcare, fintech.
Pricing: Scoped quote based on compliance scope.
Clutch Review: 4.8/5 stars based on 42 verified reviews.
Full stack team building custom RAG pipeline development and integration work, with the build and the tuning scoped as separate, transparent line items.
Key Features:
Industries Catered: Technology, professional services, custom enterprise builds.
Pricing: Scoped quote based on project size.
Clutch Review: 4.9/5 stars based on 13 verified reviews.
Patoliya Infotech builds a production-ready RAG pipeline around your actual documents, not a generic demo meant to look good once. The team handles ingestion, chunk sizing, vector storage, and reranking as a single, connected build, so nothing falls through the cracks between two specialists.
Companies that build RAG with LLM products with this team skip the usual six-month learning curve, since every RAG pipeline Patoliya ships includes a thirty-day tuning window built into the original timeline. If your current assistant guesses more than it should, book a short technical walkthrough and see exactly where retrieval is losing accuracy.
A RAG pipeline turns a model that guesses into a model that reads your actual documents before it answers. That shift is retrieval-augmented generation doing exactly what it promised, moving a chatbot from a novelty to a tool people trust with real decisions.
When you build RAG with LLM architectures, you create a foundation for accurate, context-aware AI powered by your own data. This reduces hallucinations, improves knowledge access, and delivers more reliable outcomes, ensuring users receive answers they can trust as information evolves.
Ready to see what a properly tuned RAG pipeline looks like on your own data? Let's sit down for fifteen minutes and walk through it.